CS224N Lecture 7 Machine Translation, Attention, Subword Models
Section 1: Machine Translation
机翻是一个把句子x从一种语言(源语言)翻译到另一种语言(目标语言)的句子y的任务。
1990s-2010s: Statistical Machine Translation
核心思想:从数据中学习概率模型
假设我们在翻译法语→英语
我们希望给定法语句子x,找到最好的英语句子y
使用贝叶斯法则将其分解为两个部分分开学习:
上图中,x:法语, y:英语, 机器翻译的目标就是寻找y,使得$P(y \vert x)$最大,这就是式1. 接下来,我们利用贝叶斯分解为两个概率的乘积:其中$P(y )$用之前介绍过得语言模型,从英语单语的数据中学习怎么写的通顺。最简单的就用n-gram方法。$P(y \vert x)$,是指由目标语言到源语言的翻译模型,其专注于翻译模型,翻译好局部的单词和短语,这个模型学习来自于平行的数据语料。

Learning alignment for SMT
- Q: 怎么从平行语料中学习到翻译模型$P(x \vert y)$?
- 进一步分解这个任务:引入一个模型的隐变量$a$:$P(x, a \vert y)$
- 当a是对齐的,单词程度对应着源句子x到目标句子y。可以认为是两种语言之间单词和单词或短语和短语的一个对齐关系。
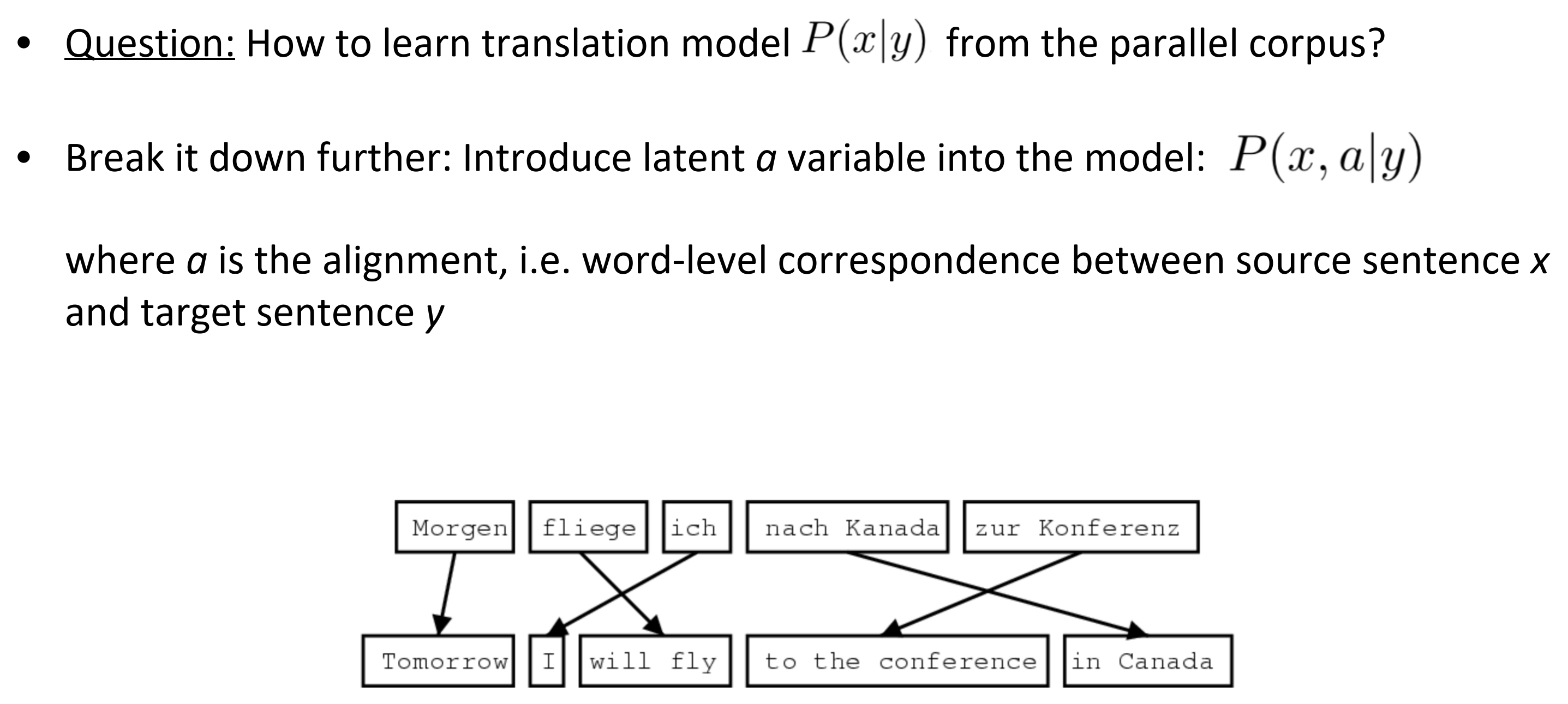
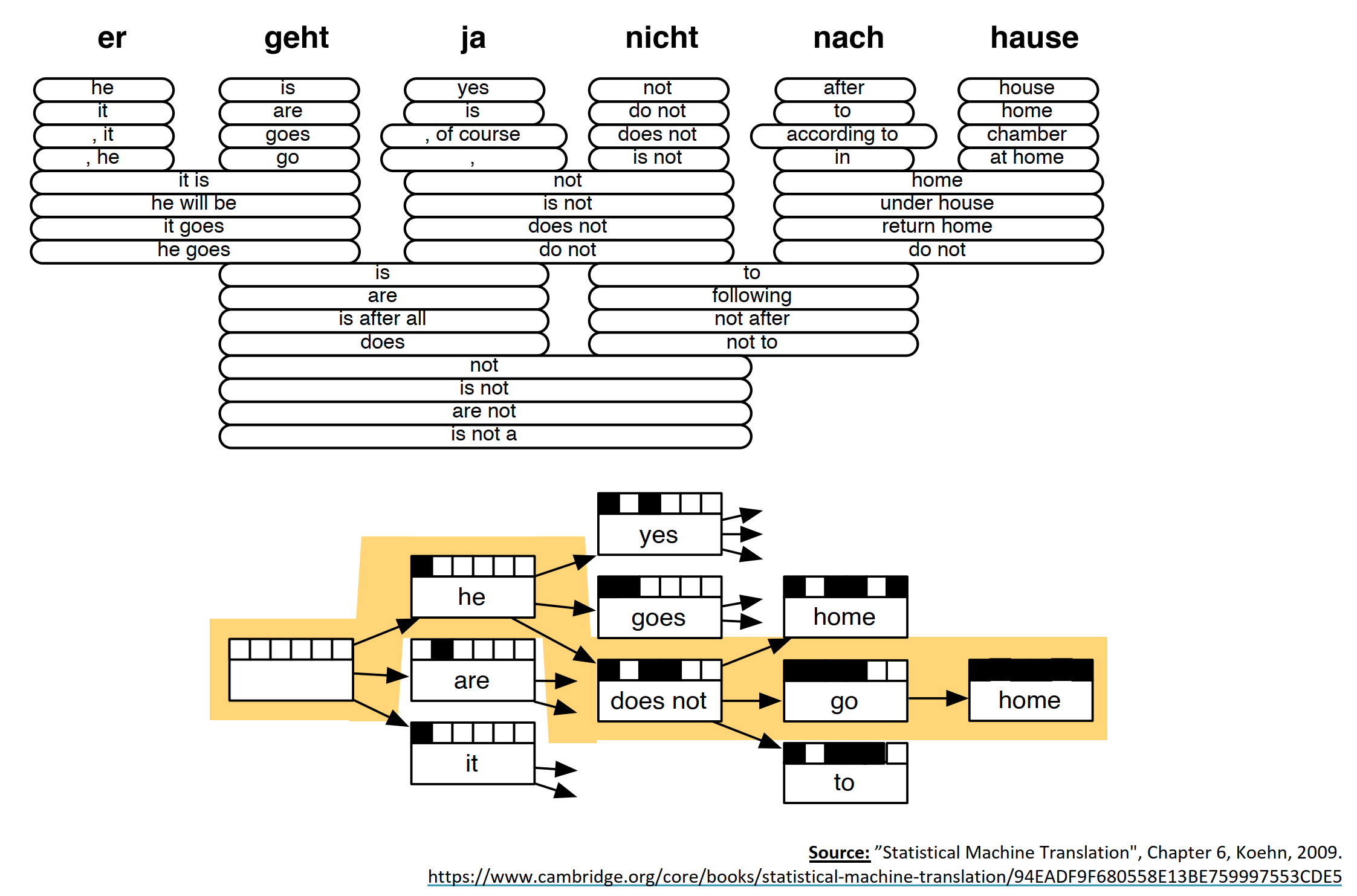
What is alignment?
对齐是在翻译句子对中指定单词的对应关系。如下图就是英语和法语的alignment。
- 不同语言直接的类型差异导致了复杂的对齐关系
- 注意:一些单词没有对应单词。

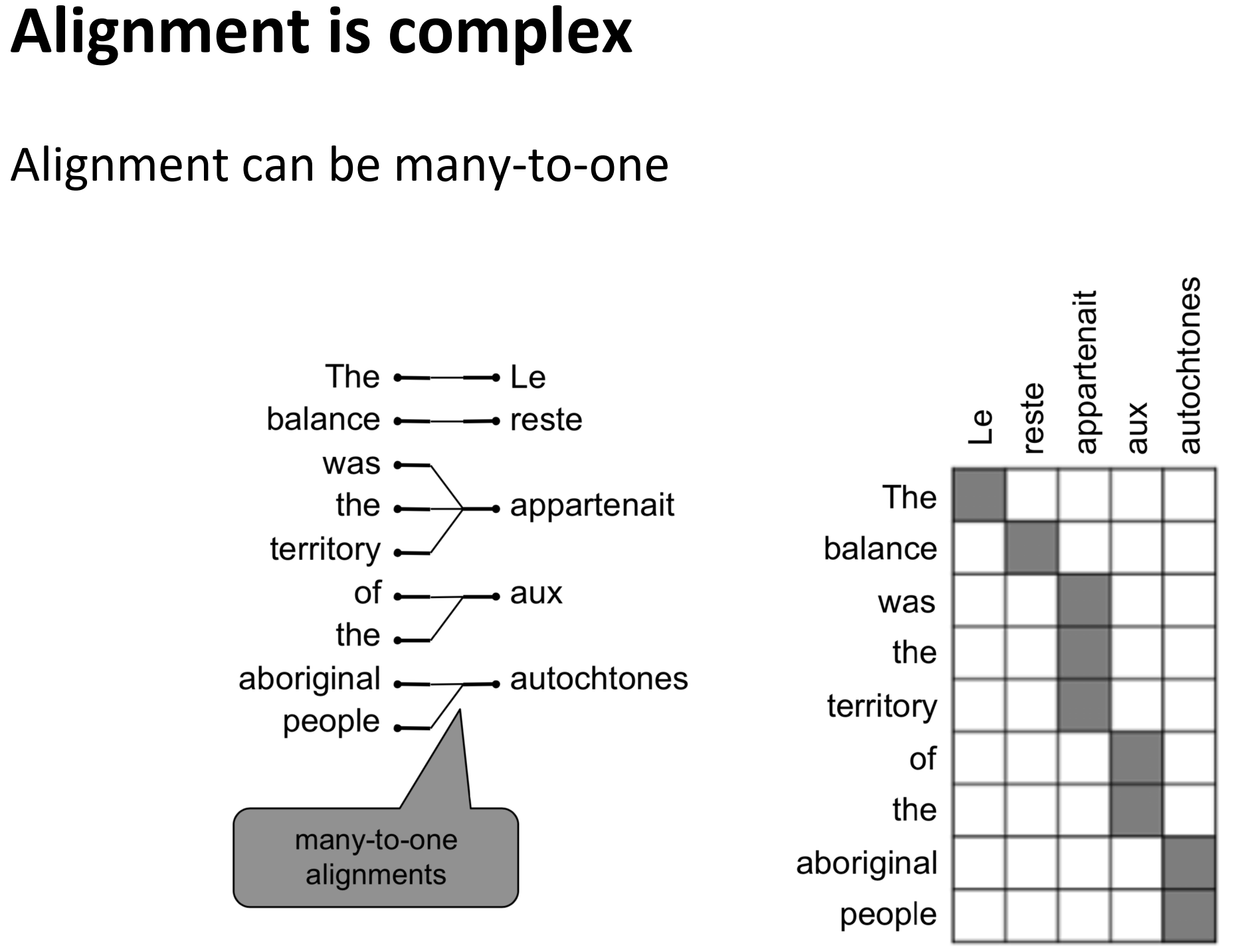
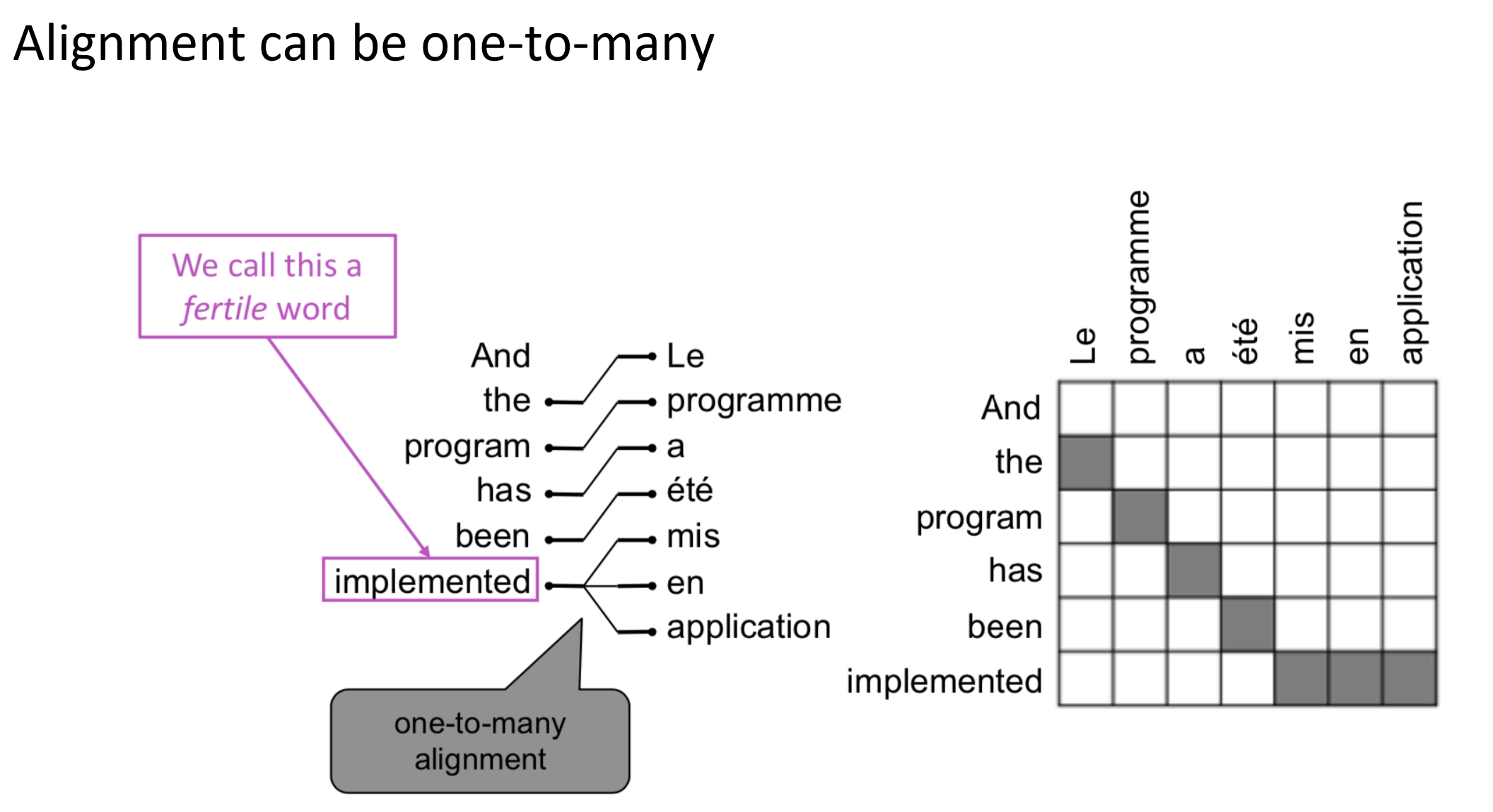
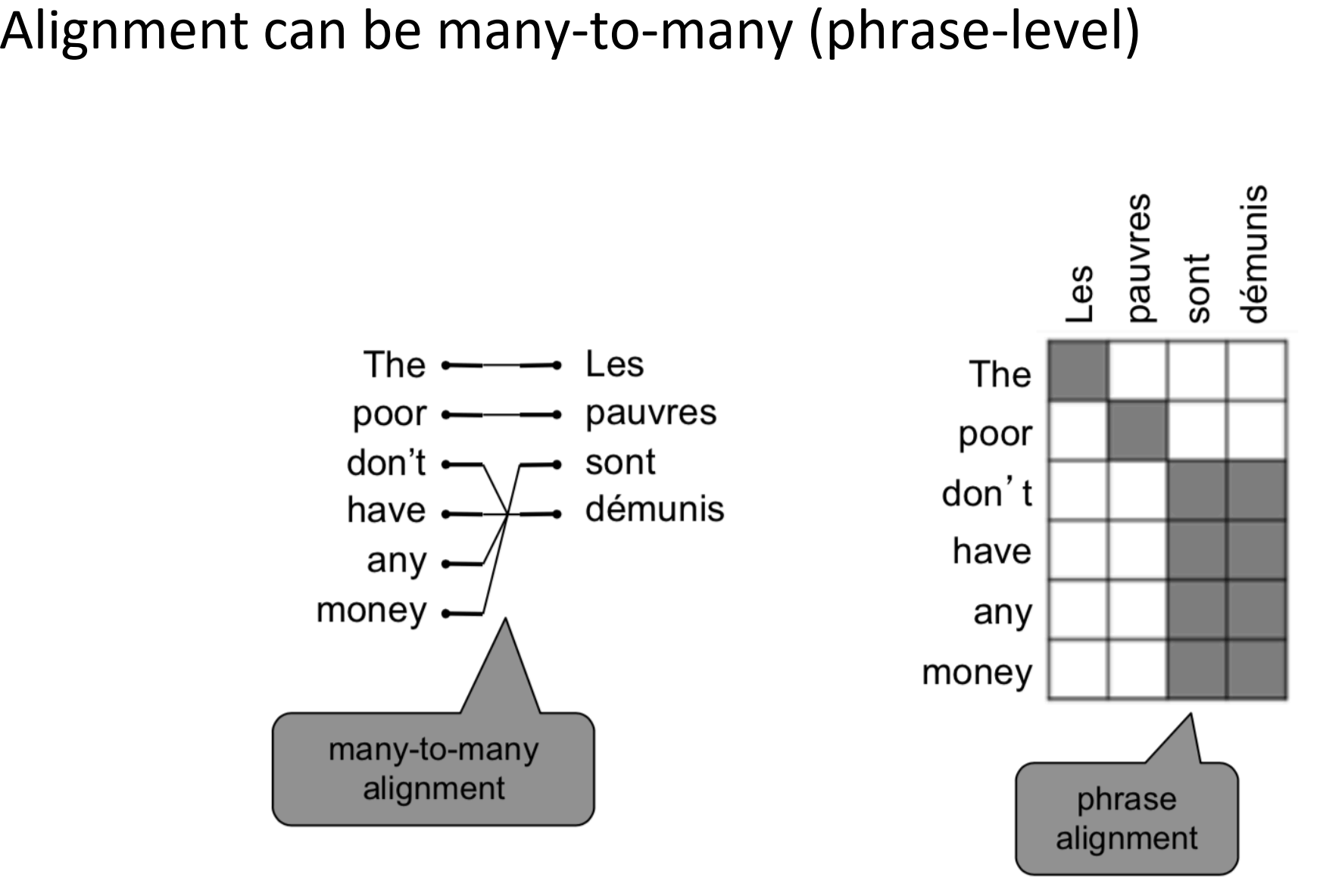
对齐是复杂的
- 多对一, 一对多, 一对一, 多对多
Learning alignment for SMT
- 我们学习$P(x, a \vert y)$作为许多组合因素,包括:
- 指定单词对齐的概率(也取决于发送的位置)
- 指定单词的概率有指定丰富关系(对应单词的数目)
- etc
- 对齐a是一个隐变量:它们在数据中不明确具体。
- 需要用特殊的算法(像最大期望算法) ,来学习有隐变量的参数分布。

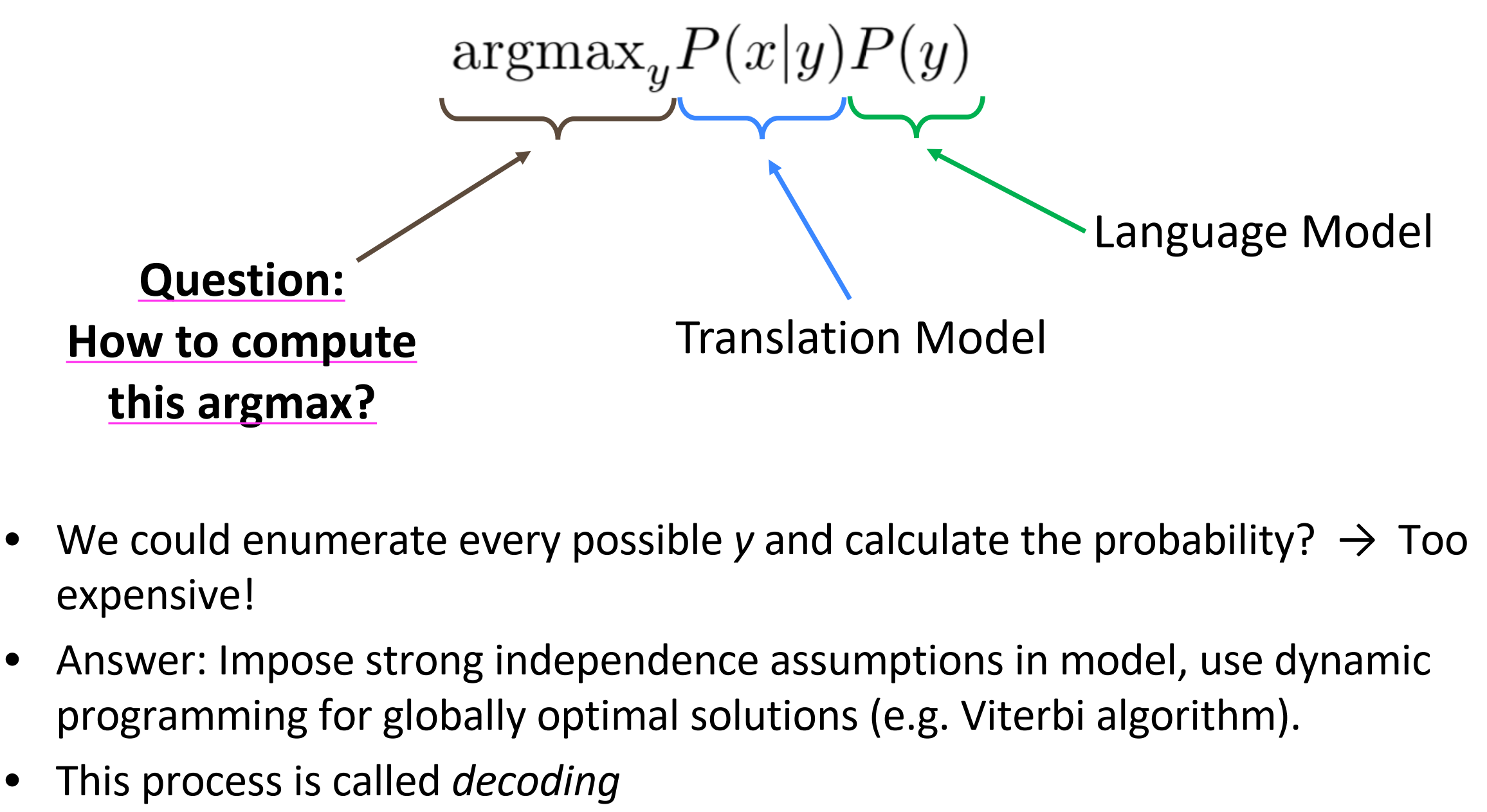
Decoding for SMT
如果计算argmax呢?
- 穷举所有可能y然后计算这个概率? 代价太大!
- 答案是: 采用模型是完全独立的假设,使用动态规划获得全局最优解(像维特比算法),启发式搜索。
- 这个过程称为解码
在搜索过程中,对概率较低的路径进行剪枝,只保留概率较大的翻译路径。如下图的搜索树,对于概率较低的路径就不往下搜索了。
1990s-2010s: 统计机翻
- SMT是一个非常大的研究领域
- 最好的系统极其复杂
- 我们还有上百个关键细节没有提到
- 系统有许多独立设计的子组件
- 许多特征工程,需要设计特征来获取指定的语言现象
- 需要编译和维护额为的资源,像相等的短语表
- 维护需要大量人力,对每个语言对进行重复艰难的尝试!

Section 2: Neural Machine Translation
What is Neural Machine Translation?
- 神经网络机翻是是用单一端对端神经网络做机翻的方式
- 神经网络架构被称为sequence-to-sequence 模型(简称seq2seq),其包含两个RNNs。

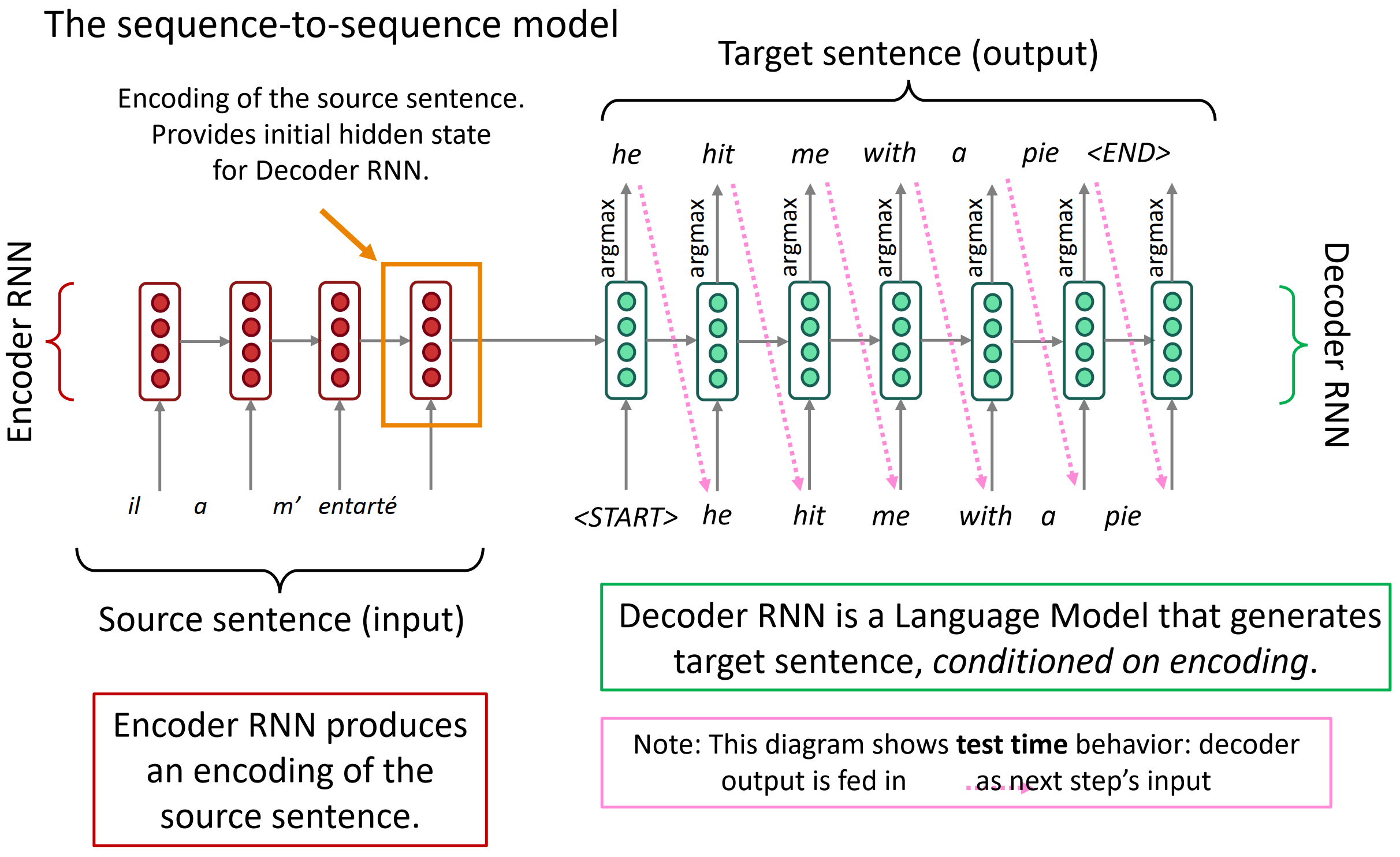
Neural Machine Translation (NMT)
seq2seq模型如下图, 它由两个RNN构成。左边红色部分是Encoder RNN,它负责对源语言进行编码;右边的绿色部分称为Decoder RNN,它负责对目标语言进行解码(Decode)。首先,Encoder RNN可以是任意一个RNN,比如朴素RNN、LSTM或者GRU。Encoder RNN负责对源语言进行编码,学习源语言的隐含特征。Encoder RNN的最后一个神经元的隐状态作为Decoder RNN的初始隐状态。Decoder RNN是一个条件语言模型,一方面它是一个语言模型,即用来生成目标语言的;另一方面,它的初始隐状态是基于Encoder RNN的输出,所以称Decoder RNN是条件语言模型。Decoder RNN在预测的时候,需要把上一个神经元的输出作为下一个神经元的输入,不断的预测下一个词,直到预测输出了结束标志符
Seq2seq是很强大的模型不仅仅用于MT,还有许多NLP任务能变大为seq2seq:
- 文本概括
- 对话
- 解析
- 代码生成

- seq2seq是一个条件语言模型的例子
- LM因为解码是预测目标句子y的下一个词
- 条件是因为它预测也是建立在源句子x条件上
- NMT直接计算$P(y \vert x)$,如下图中所示。
那么问题来了,怎么训练NMT系统呢?
- 找一个大的平行语料

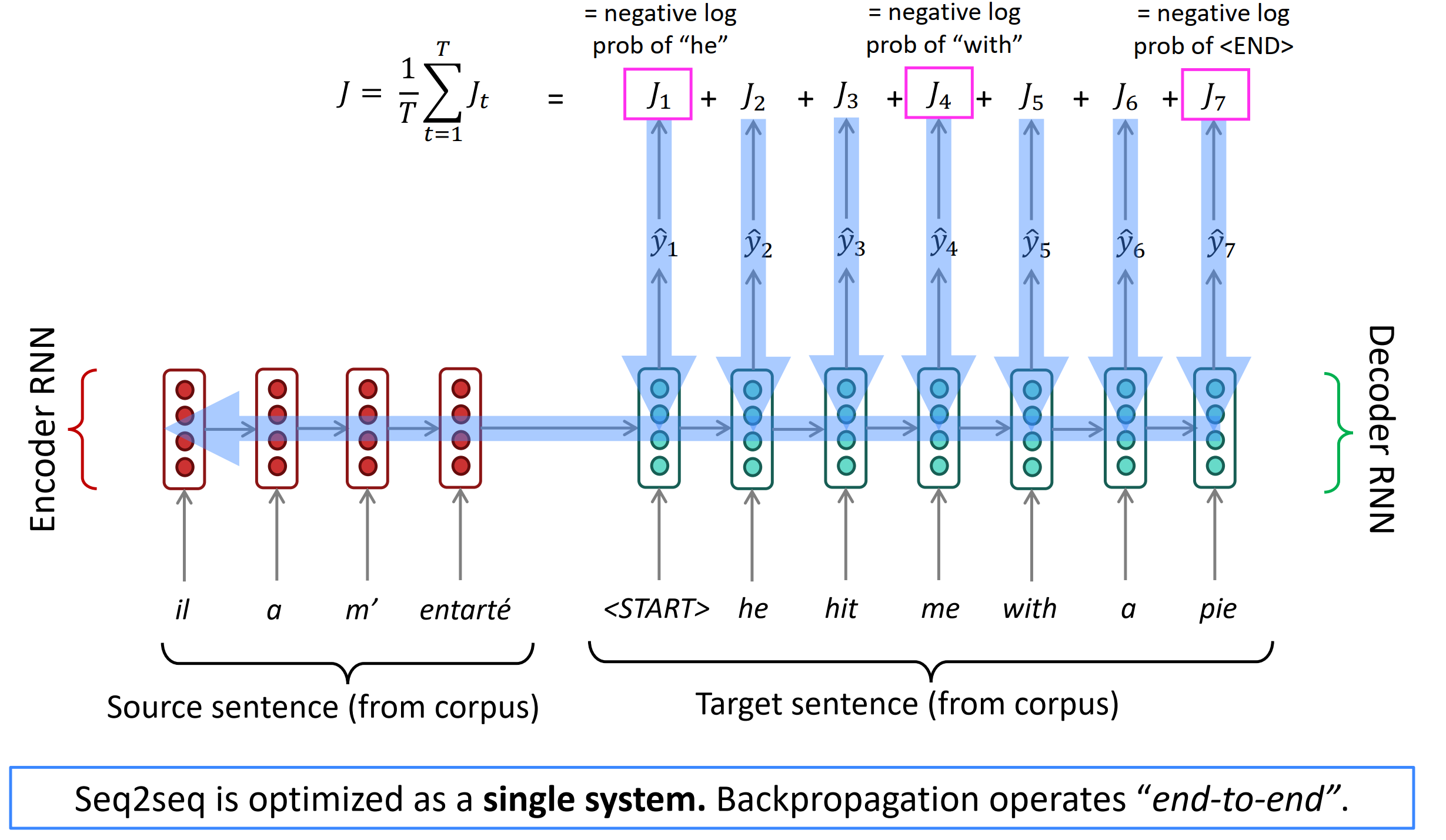
Training a Neural Machine Translation system
seq2seq被优化为一个单一系统。反向传播训练是“端对端”。如下图所示,将Encoder
Multi-layer RNNs
多层RNNs:
- RNNs已经是在一个维度上是“深”的(将其展开成许多时刻)
- 我们也可以让其在另外的维度上变“深”,就通过应用多个RNNs——变成多层的RNN。
- 允许网络计算更复杂的表示,低层的RNNs应该计算低层的特征高层RNNs应该计算高层的特征
- 多层RNNs也叫堆叠RNNs

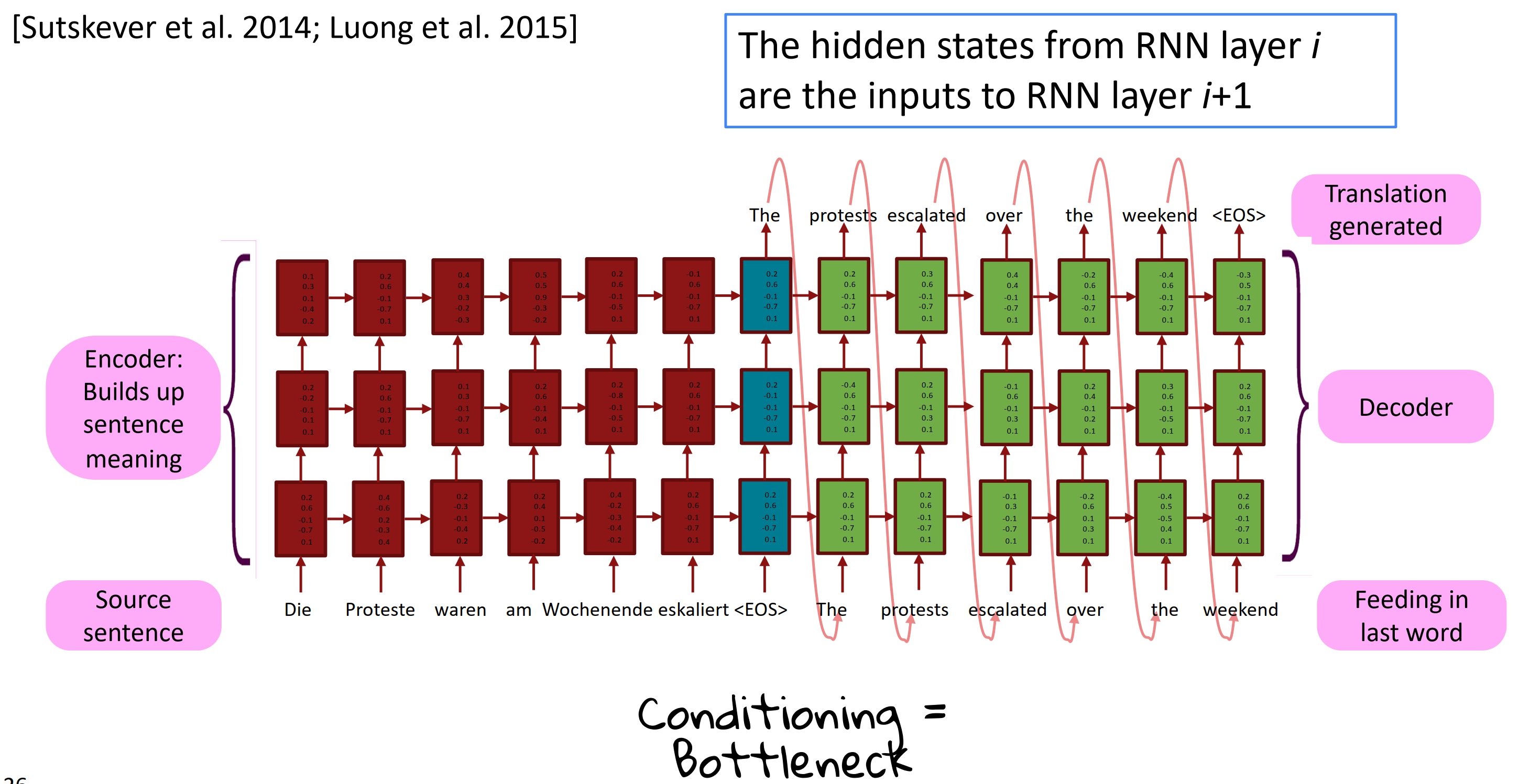
Multi-layer deep encoder-decoder machine translation net
多层深度编码-解码机翻网络
来自RNN第i层的隐状态是RNN第i+1层的输入;左边红色部分多层RNN堆叠在一起作为编码器,来构建源句子的意思;右边绿色部分作为解码器来生成翻译。中间就像个瓶颈一样,叫做bottleneck。实际上多层RNNs应用技巧看上篇笔记。
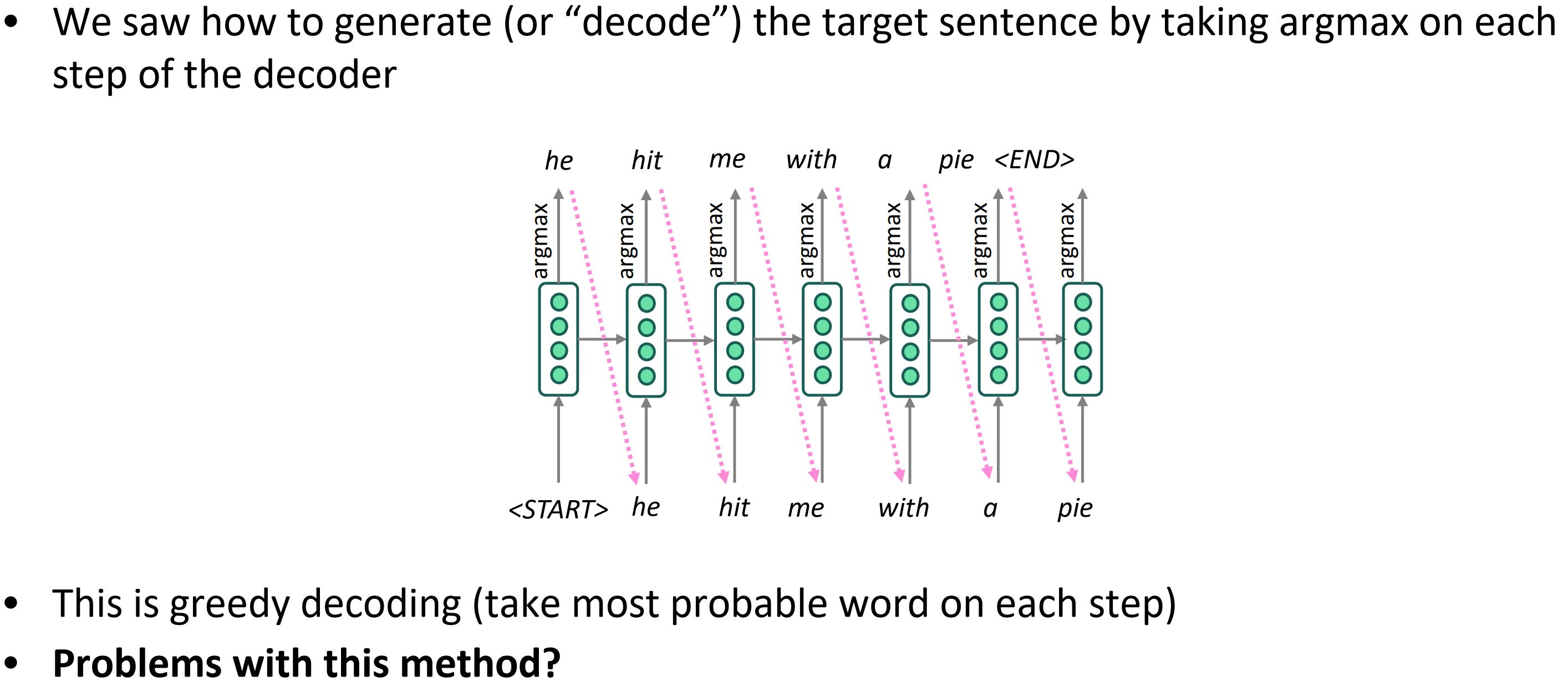
Greedy decoding
- 我们看到怎样生成(或者说“解码”)目标句子,在解码的每个时间序列上采用argmax。
- 这就是贪婪解码(的在每个step上取最可能的单词)
- 这个方法的问题?
Problems with greedy decoding
- 贪婪解码没有办法回溯,那怎么修复这个问题呢?

Exhaustive search decoding
穷举搜索解码
- 理想情况下,我们想要找到一个(长度为T)让y最大化的翻译,如下图所示
- 我们尝试计算所有可能的序列y
- 这意味着在解码器的每个step,我们遍历$V^t$个可能的部分翻译,其中$V$是词汇表的size,$O(V^t)$时间复杂度太高了!

Beam search decoding
束搜索解码
- 核心思想:在解码器每一个step上,遍历k个最可能的部分翻译(这个我们叫假设)
- k是约束大小(实际上值为5-10)
- 假设$y_1, \cdots, y_t$有一个其对数概率的分数,如下图所示
- 所有分数是负数,分数越高表示更好的结果
- 我们在每个step上遍历Top-k个来搜索高分数假设,这里Top-k不仅仅是当前$\hat y$最高的几个概率,而是截止到目前这条路径上的累计概率之和。
- 束搜索不确保找到最优解
- 但比穷举搜索更有效率

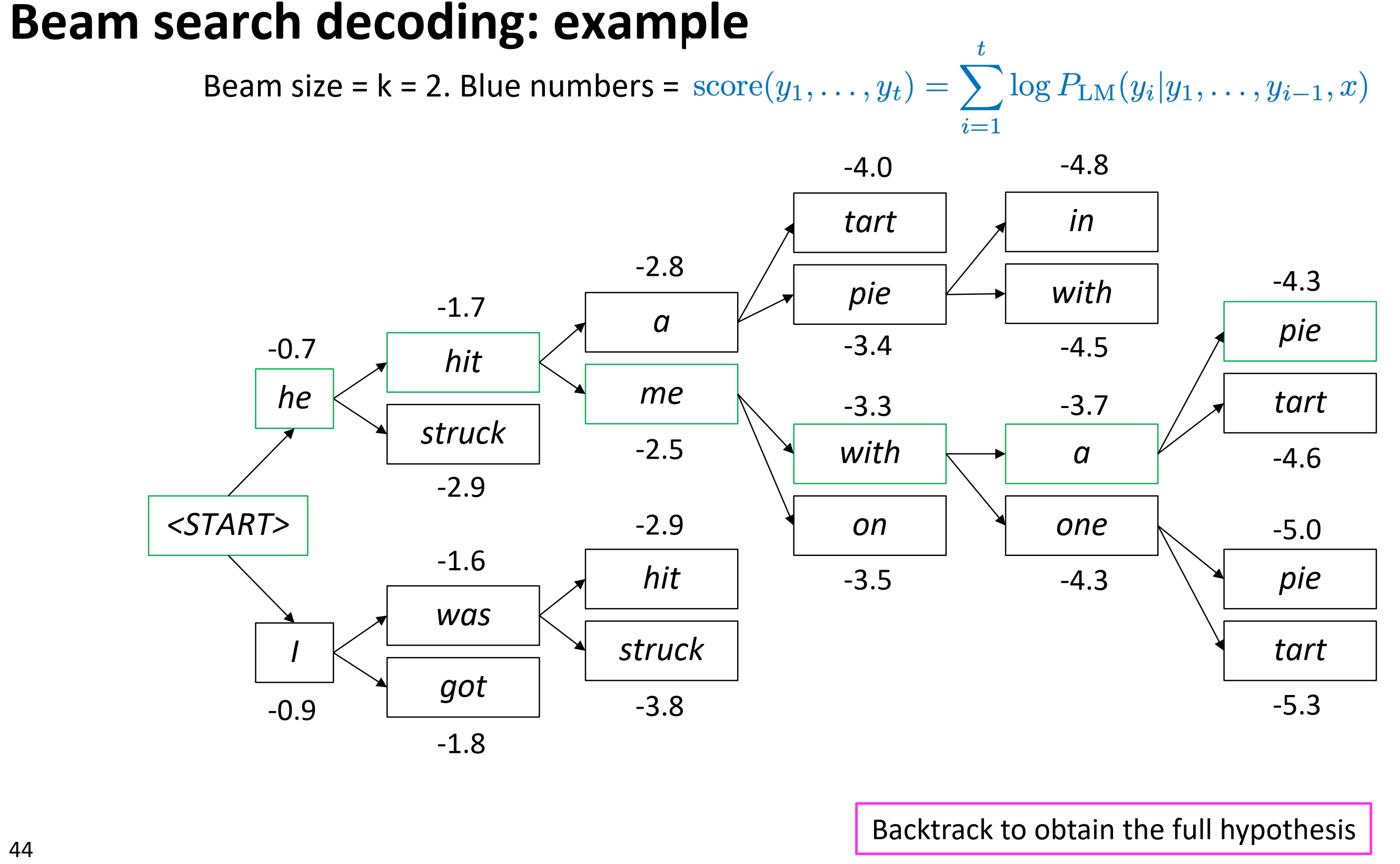
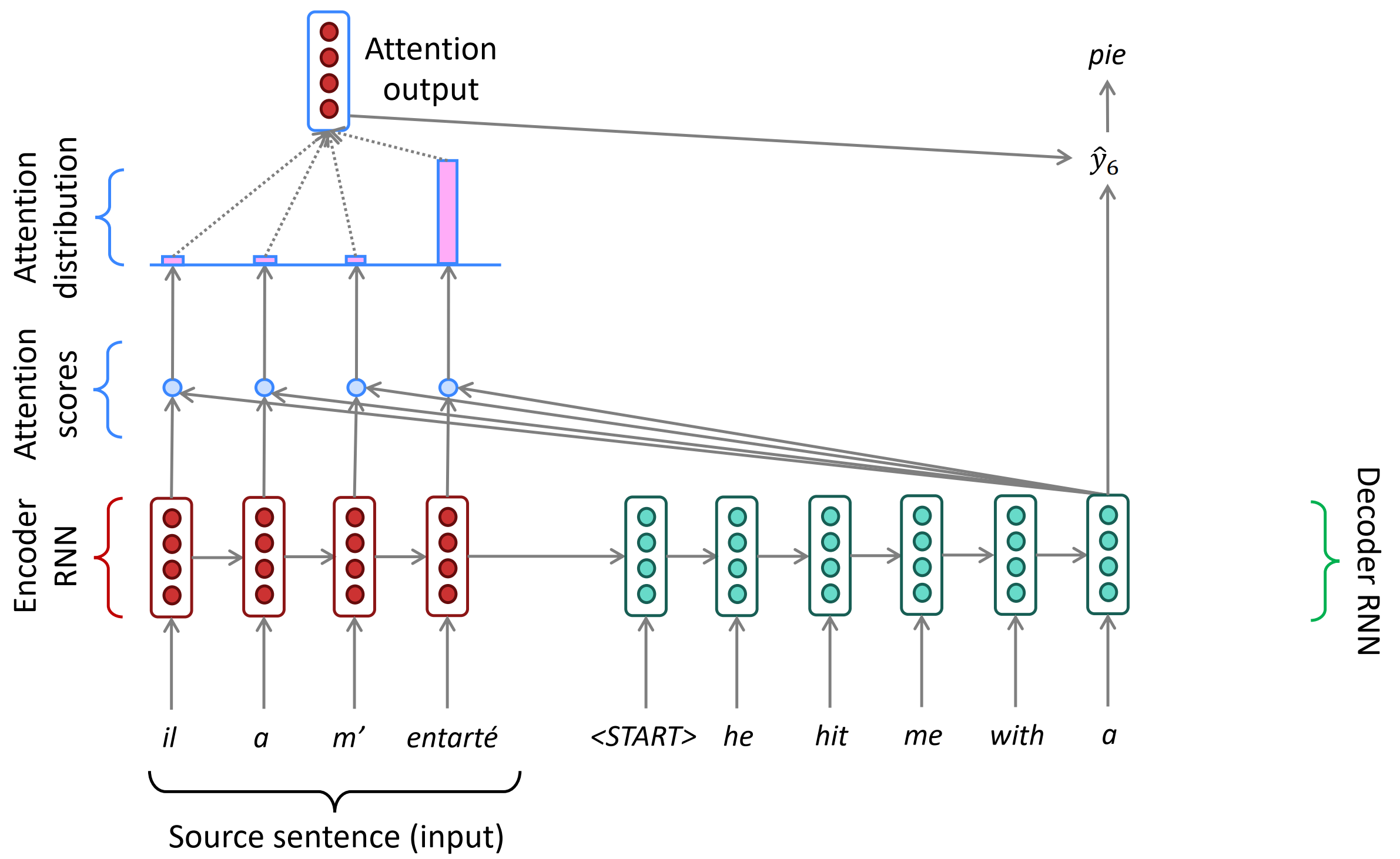
如下图中,束搜索size=2时,第一个timestep保留的Top-2词为he和I,它们分别作为下一个timestep的输入。
he输入预测输出Top-2是hit和struck,hit这条路径上累加概率是 he加上 hit为-1.7。同样计算其它词对应路径的概率分数。最后在这4条路径上保留$k=2$条路。所以保留 hit和 was。将其作为下一个timestep的输入;那么 struck和 got对应路径应该被剪枝。这就是,对k个假设逐个,找到top k下一个词并计算其分数。

再下一个timestep同样计算,剪枝后保留a和me。

最终搜索树如下图所示,以看到在每个时间步都只保留了k=2个节点往下继续搜索。最后pie对应的路径打分最高,通过回溯法得到概率最高的翻译句子。请注意,束搜索作为一种剪枝策略,并不能保证得到全局最优解,但它能以较大的概率得到全局最优解,同时相比于穷举搜索极大的提高了搜索效率。
Beam search decoding: stopping criterion
束搜索解码:停止标准
- 在贪婪解码里,通常我们解码知道模型输出一个
<END>结束标志符。- 例子:
<START>he hit me with a pie<END>
- 例子:
- 在束约束搜索解码里,不同路径预测输出
<END>结束标志符的timestep可能不一样,有些路径可能提取结束了,称为完全路径,暂时把这些完全路径放一边,其他路径接着束搜索。 - 通常我们继续束搜索直到:
- 我们达到timestep T(其中T是提取设置的中断条件)
- 或者我们至少有n个完成的路径(其中n是提取设置的中断条件)

Beam search decoding: finishing up
束搜索解码:结束
- 我们有了完全的假设(路径)列表。
- 怎么选择有最高分的top one?
- 每个假设$y_1, \cdots, y_t$在列表里都有一个分数,如下图。
- 问题在于:假设越长,分数越低。在搜索路径上,累加得越多分越低,所有根据长度对打分进行归一化。

NMT相比于SMT的优点:
- 性能更好,表现在:翻译更流程,RNN擅长语言模型;能更好的利用上下文关系;能利用短语相似性
- 模型更简单,只需要一个神经网络,端到端训练即可,简单方便
- 不需要很多的人工干预和特征工程,对于不同的语言,网络结构保持一样,只需要换一下词向量
NMT的不足:
- 难以解释,表现在:难以调试,难以解释出错原因
- 难以控制,比如难以加入一些人工的规则,难以控制NMT不输出什么,由此可能会脑一些笑话甚至导致安全问题
How do we evaluate Machine Translation?
怎么评价机翻?
BLEU (Bilingual Evaluation Understudy )
- BLEU将机翻和人工翻译(一个或多个)进行比较重叠部分,具体公式看Assignment 4,然后基于这个计算一个相似分数
- n-gram精度
- 过短的机翻加上一个惩罚
- BLEU 有用但不完美
- 有许多有效的方法来翻译一个句子
- 所以一个好的翻译可能得到一个糟糕的分数因为它和人工翻译有较低的n-gram重叠

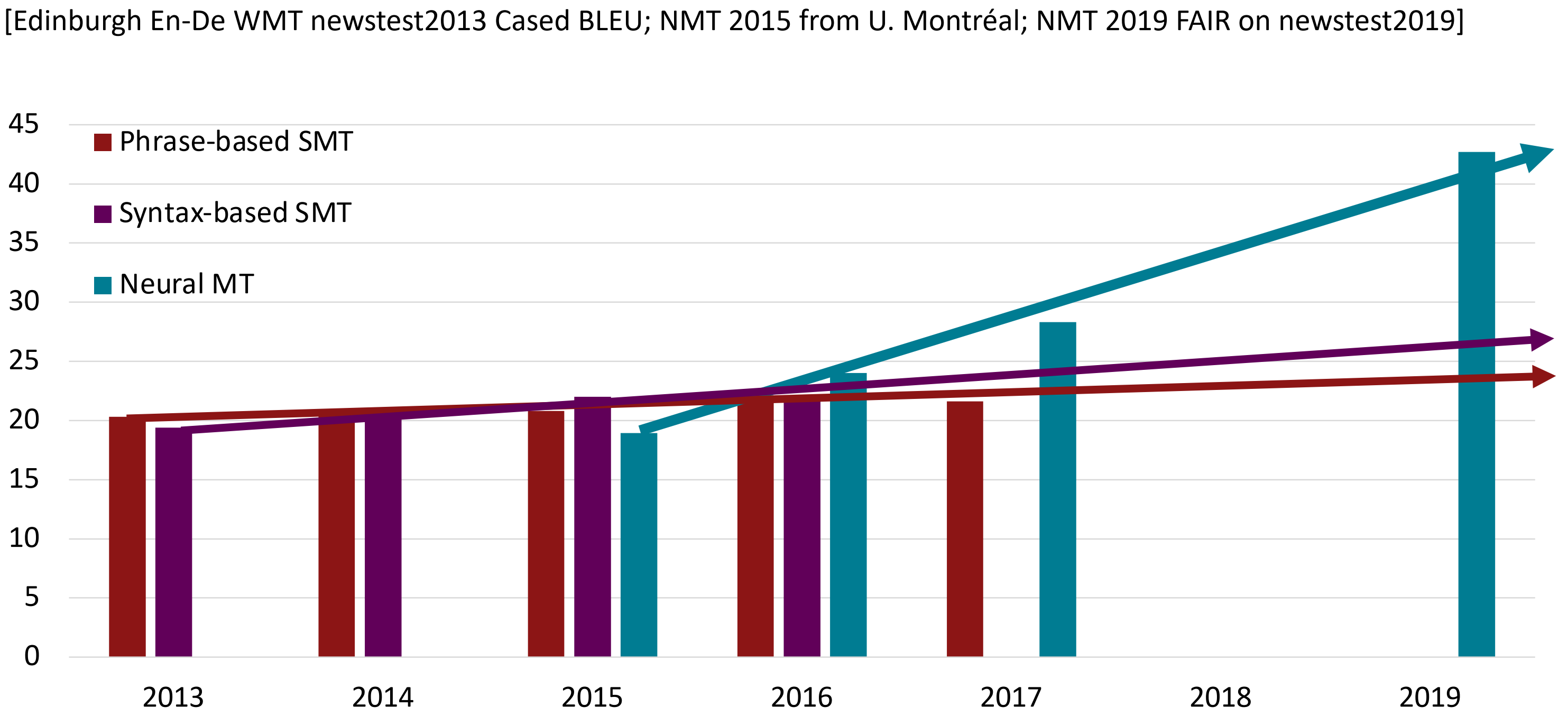
MT progress over time
数据来源于(http://www.meta-net.eu/events/meta-forum-2016/slides/09_sennrich.pdf)
神经机器翻译于2014年从边缘研究活动到2016年成为领先标准方法
- 2014:第一篇 seq2seq 的文章发布
- 2016:谷歌翻译从 SMT 换成了 NMT
- 这是惊人的,由数百名工程师历经多年打造的SMT系统,在短短几个月内就被少数工程师训练过的NMT系统超越
So is Machine Translation solved?
- 不!
- 许多困难仍然存在
- 词表外的单词处理
- 训练和测试数据之间的 领域不匹配
- 在较长文本上维护上下文
- 资源较低的语言对
- 使用常识仍然很难
NMT research continues
NMT是NLP深度学习的旗舰
- NMT研究引领了NLP深度学习的许多创新
- 在2021:NMT研究继续蓬勃发展
- 研究这已经找到许多,许多改进在我们刚刚提到的“原生的” seq2seq NMT系统
- 但是我们将在接下来介绍新的一种不可或缺的改进——Attention!

Section 3: Attention
Sequence-to-sequence: the bottleneck problem
seq2seq: 瓶颈问题
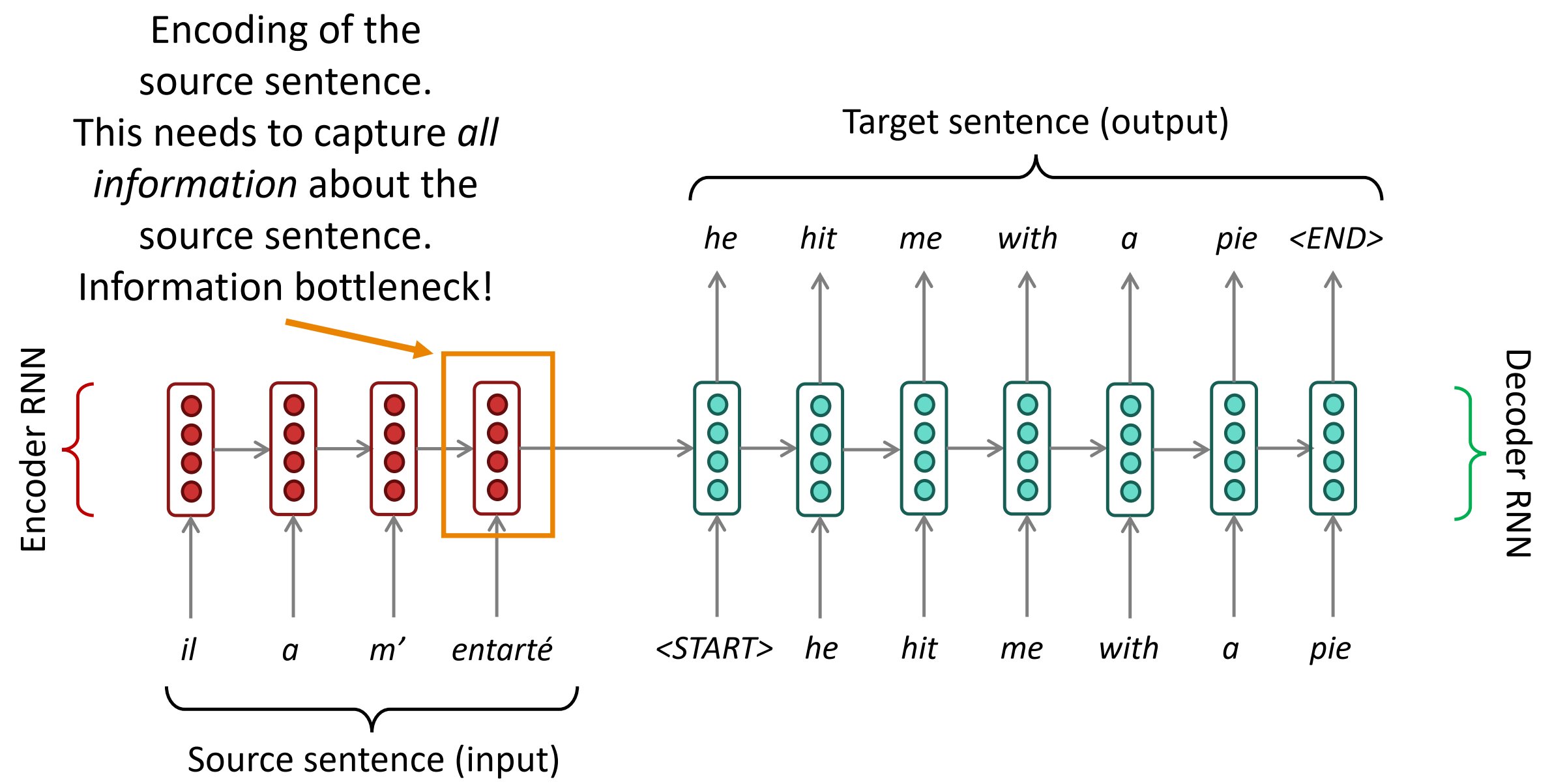
在下图中,Encoder RNN 的最后一个神经元的隐状态作为Decoder RNN的初始隐状态,也就是说Encoder的最后一个隐状态向量需要承载源句子的所有信息,成为整个模型的“信息”瓶颈。
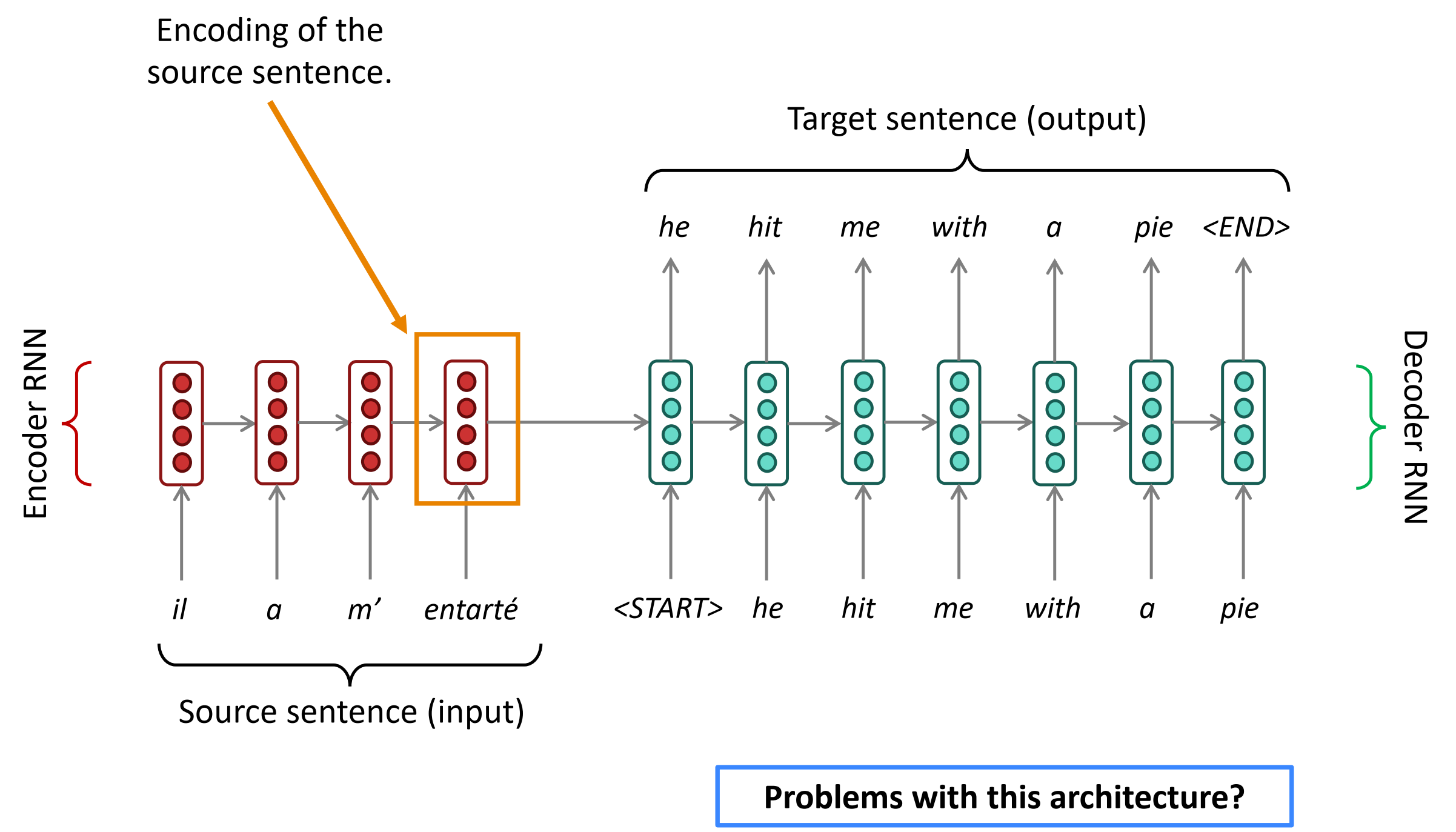
在最后一个隐藏状态,需要获取的全部关于源句子的信息。这就是瓶颈问题。
Attention
- 注意机制提供了解决瓶颈问题的方法
- 核心思想:在每一步都解码,用直连解码器来专注于源句子中特殊的部分
- 开始我们用图来说明,然后用方程。
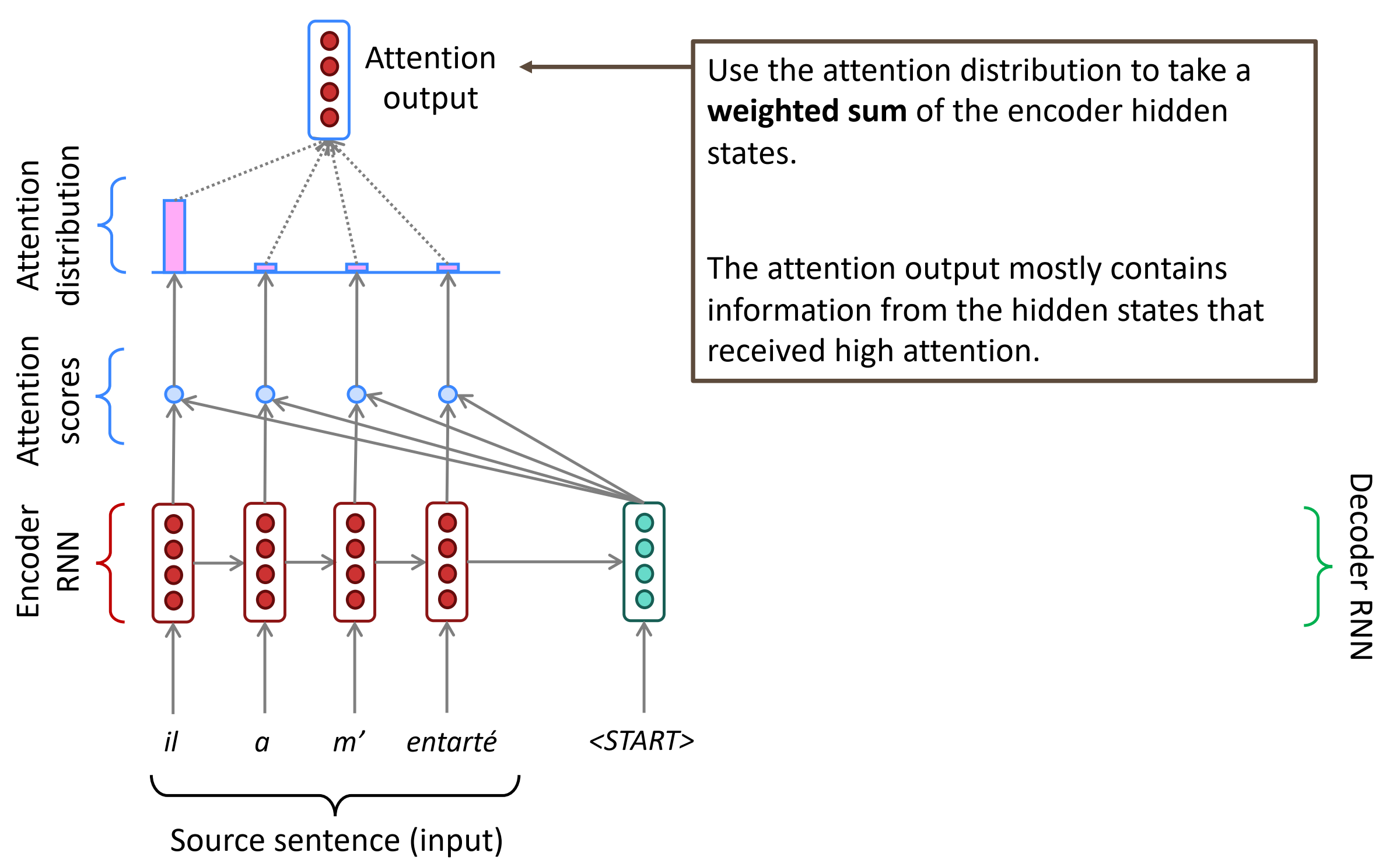
Sequence-to-sequence with attention
具体来说,在时刻t,Decoder第t时刻的隐状态$s_t$和Encoder所有时刻的隐状态$h_1, \cdots, h_n$做点积,得到N个标量Attention score,作为Encoder每个隐状态的权重,然后使用softmax对这些权重进行归一化,得到Attention distribution。这个Attention distribution相当于Decoder在时刻t对Encoder所有隐状态的注意力分布,如下第3张图所示,”he”时刻的注意力主要分布在Encoder的第2和第4个词上,这不正是前面介绍的SMT的对齐alignment操作吗!Attention自动学习到了这种对齐操作,只不过是soft alignment。
接下来,对Encoder所有隐状态使用Attention distribution进行加权平均,得到Attention output $a_t$。把$a_t$和该时刻的隐状态$s_t$拼起来再进行非线性变换得到输出$\hat y_2$。有时,也可以把上一时刻的Attention output和当前的输入词向量拼起来作为一个新的输入,输入到Decoder RNN中。
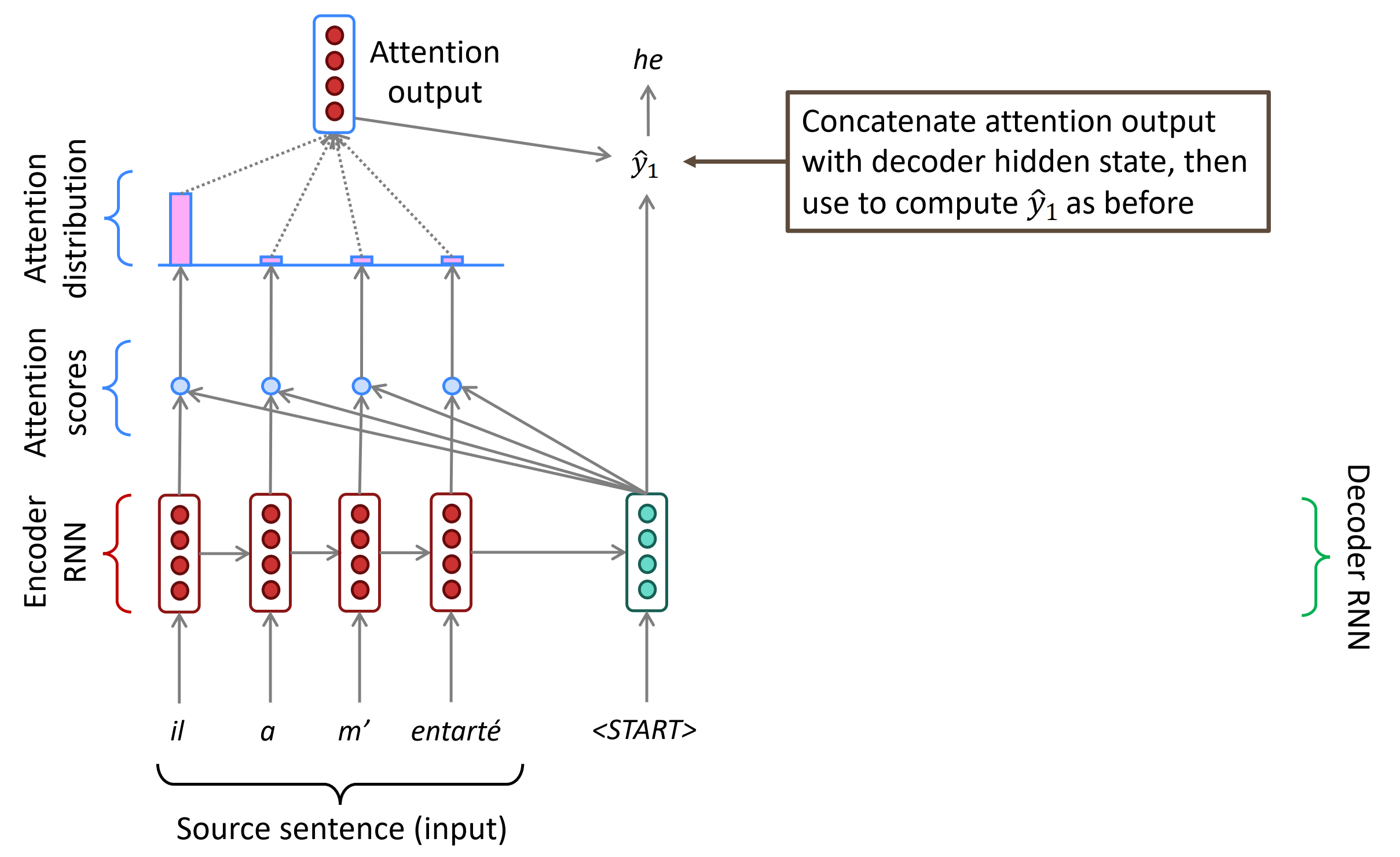
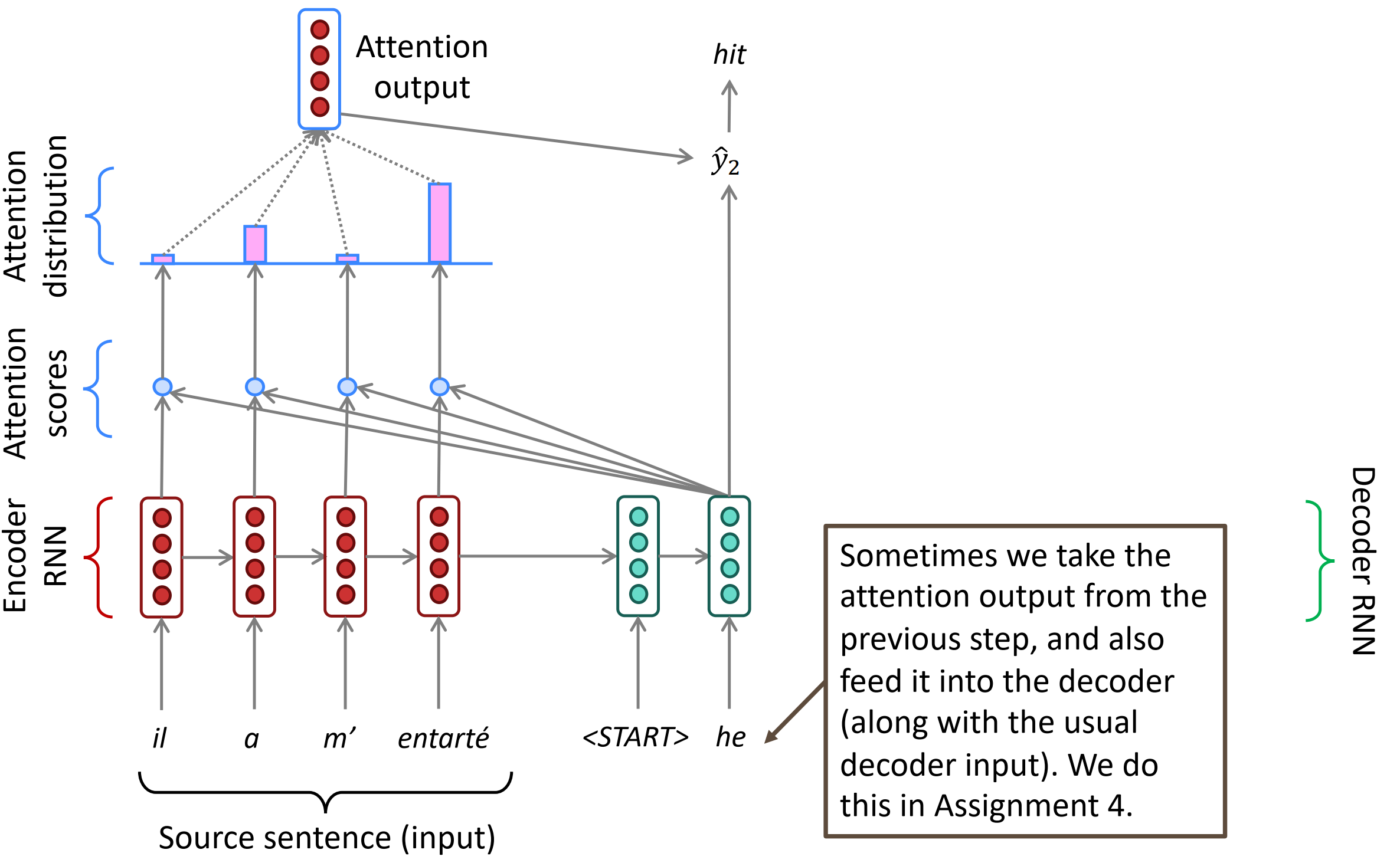
Attention: in equations
- 编码器的隐状态$h_1, \cdots, h_n \in \mathbb{R}^h$
- 在timestep $t$, 解码器隐状态为$s_t \in \mathbb{R}^h$
- 得到该时刻$t$的注意力分数
- 对$\mathbf{e}^t $取softmax得到注意力分布$\mathbf{\alpha}^t $(这是一个概率分布,和为1)
- 将$\mathbf{\alpha}^t $ 和编码器隐状态$\mathbf{h} $点乘得到注意力输出$\mathbf{a}_t $
- 最后,将注意力输出$\mathbf{a}_t $和解码器隐状态$s_t$拼起来,并按照非注意力seq2seq模型运行$[\mathbf{a}_t; \mathbf{s}_t ] \in \mathbb{R}^{2h}$

Attention is great
- 注意力显著提高了NMT性能
- 这是非常有用的,让解码器专注于某些部分的源语句
- 注意力解决瓶颈问题
- 注意力允许解码器直接查看源语句;绕过瓶颈
- 注意力帮助消失梯度问题
- 提供了跟短接远处状态的方式
- 注意力提供了一些可解释性
- 通过检查注意力的分布,我们可以看到解码器在关注什么
- 我们可以轻松得到(软)对齐
- 这很酷,因为我们从来没有明确训练过对齐系统
- 网络只是自主学习了对齐

Attention is a general Deep Learning technique
- 我们已经看到attention是一种改进机翻的seq2seq模型很好的方法
- 然而,你可以在许多架构中用attention
- 注意力更普遍的定义是:
- 给定一系列向量的值,或者向量查询队列,attention是一种计算关于查询队列与向量值权重和的技术
- 我们有时说,查询注意到哪些值
- 例如,在seq2seq + attention 模型中,每个解码器的隐状态查询注意到首页解码器隐状态的某一些值。

直觉
- 加权和是值中包含的信息的选择性汇总,查询在其中确定要关注哪些值
- 注意是一种获取任意一组表示(值)的固定大小表示的方法,依赖于其他一些表示(查询)。

There are several attention variants
- 一个值的集合$\mathbf{h}_1, \cdots, \mathbf{h}_n \in \mathbb{R}^{d_1}$,一个 查询$\mathbf{s} \in \mathbb{R}^{d_2}$
- Attention总是包括
- 计算注意力分数
- 对分数取softmax得到注意力分布
- 用注意力分布对隐状态值求权重和来获得注意力输出$\mathbf{a}$

Attention 变种
其实就是计算从编码器隐状态$\mathbf{h}_1, \cdots, \mathbf{h}_N \in \mathbb{R}^{d_1}$和解码器隐状态$\mathbf{s} \in \mathbb{R}^{d_2}$计算attention分数$\mathbf{e} \in \mathbb{R}^{N}$的几种方式:
- 基本点积注意力:$\mathbf{e}_i = \mathbf{s}^T \mathbf{h}_i \in \mathbb{R}$,注假设$d_1= d2$,这就是我们之前见到的
- 乘法注意力:$\mathbf{e}_i = \mathbf{s}^T \mathbf{W} \mathbf{h}_i \in \mathbb{R}$, 其中$\mathbf{W} \in \mathbb{R}^{d_2 \times d_1}$是权重矩阵
- 加法注意力:$\mathbf{e}_i = \mathbf{v}^T \text{tanh }(\mathbf{W}_1 \mathbf{h}_i + \mathbf{W}_2 \mathbf{s}) \in \mathbb{R}$. 其中$\mathbf{W}_1 \in \mathbb{R}^{d_3 \times d_1}, \ \mathbf{W}_2 \in \mathbb{R}^{d_3 \times d_2}$是权重矩阵,$\mathbf{v}\in \mathbb{R}^{d_3}$是权重向量,$d_3$是超参数

总结

参考
[2] cs224n-2019-notes06-NMT_seq2seq_attention
[3] Deep Learning for NLP Best Practices
[4] CS224N(1.31)Translation, Seq2Seq, Attention
[5] Machine Translation, Seq2Seq and Attention
[6] Science is interesting.08 Machine Translation, Sequence-to-sequence and Attenti
 wechat
wechat alipay
alipay




